谈谈 AI 流程
目前市面上冒出的什么新型LLM工具,基本上可以总结为IO包装工具。
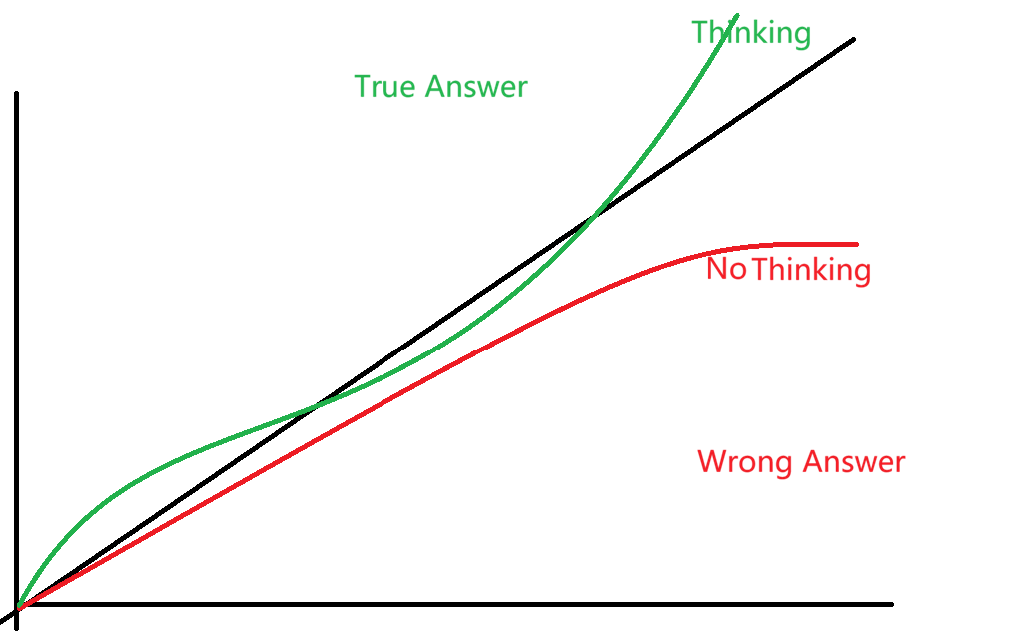
从Tools-call到Thinking,从MCP到COT,无不是结构化输出的结果。
LLM只会根据输入的Token和参数例如Top_K、Temperature改变概率选择的倾向导致结果的不同,他始终在输出文本,而调用工具等全都是后期大量结构化数据对模型进行后训练、微调诞生的结果。
就例如Thinking,本质上就是模型输出一段<thinking>…</thinking>标签包裹的文本,但是后期的训练让模型学会在Thinking标签中不断通过自我纠正,使得自身后续的输出Token的概率选择倾向更加朝着正确答案靠拢。
而工具调用也一样——同样是结构化输出,模型输出一段<tool_call>{…}</tool_call>,然后处理的代码部分识别到了工具调用,自动直接中断模型,并返回解析好的工具调用。
这就是LLM本质——一个纯Token的输入/输出机器——他不会像你的任何代码一样能够自己去执行一段真正的操作,而只是源源不断通过概率计算输出Token。
谈谈 中断
这时候你的代码开始火急火燎的处理工具调用,返回给模型,但是模型并不会因此Recover——这一次模型的Thinking Brain已经死了,因为他已经被中断了,因为输出的Token是一个序列,本质上你可以抽象为LLM是一个输入-输出序列的函数:
这就很绝望——在这个Transformer架构下我们无法通过类似于断点续传的操作让模型不中断而更新他的上下文——哪怕只是Append。
这就像你走进了传送机,但是传送机只是读取了你全身的原子数据,然后销毁你现在的身体,把你的身体在另一个地方重建。
这就是Truth。我们只能另起一个序列,通过把你的工具调用结果拼接在之前的上下文后边:
让模型继续推理,得到的数列C和拼接起来的A就是你拿到的最终答案。
在这篇论文中,他们通过注入编译器权重,实现了一个在输出Token链过程”执行“WASM代码的过程——通过Transformer和他们的架构进行特定的固定运算从而实现精确模拟的计算机执行过程。
让我们想想,假如我们能够修改模型运行过程的计算图的某些数值,通过解析Attention和FFN的某些运算逻辑,实现从外部实时注入一些工具的运算结果?
谈谈 Agent 工程
Agent的工程方面有很多非常之美的实现——OpenClaw的定时唤醒和子Agent任务、记忆机制,Codex, Antigravity等的压缩机制,Skill等。
我们不难发现,这些热点本质上都是在对AI执行流程进行创新,解决了不同的痛点。
从最早期的GPT-3的单纯QA流程——纯对话,发展到现在的起床就能看OpenClaw给你发消息,Codex帮你码代码,OpenCode帮你修服务器运维问题,我们最大的变化就是本质上没有变化。
模型输出的依旧是那些转化后的纯文本,而我们的体验确实是不断地变高。
这就是Agent工程。
谈谈 受益
在这LLM当下的发展进度当中,在我看来,没有人受害。
LLM替代了码农——替代的是那些没有坚实计算机理解和思考能力的人。
就像前几周炒作的”文科生组建AI大军干爆工科生“云云,你能指望一个没有计算机基础、没有基础编程能力的人,单纯靠LLM且过程中不学习,能够码出不会冲突、有问题的代码,能够精确的测试和编写提示词指出问题所在?
学生得到了一个比肩高材生的家教学习机会,码农得到了能够省去重复编写代码和快速构建代码的工具,普通人得到了一个能够随便玩玩就能写出方便自己或者比较好玩的软件的能力。
至少在当下,能最好驾驭模型的还是这些熟悉计算机的人。
谈谈 向量维度
向量维度其实是一个非常好谈的话题。
想象一个向量:
这个向量在一个三维空间中。
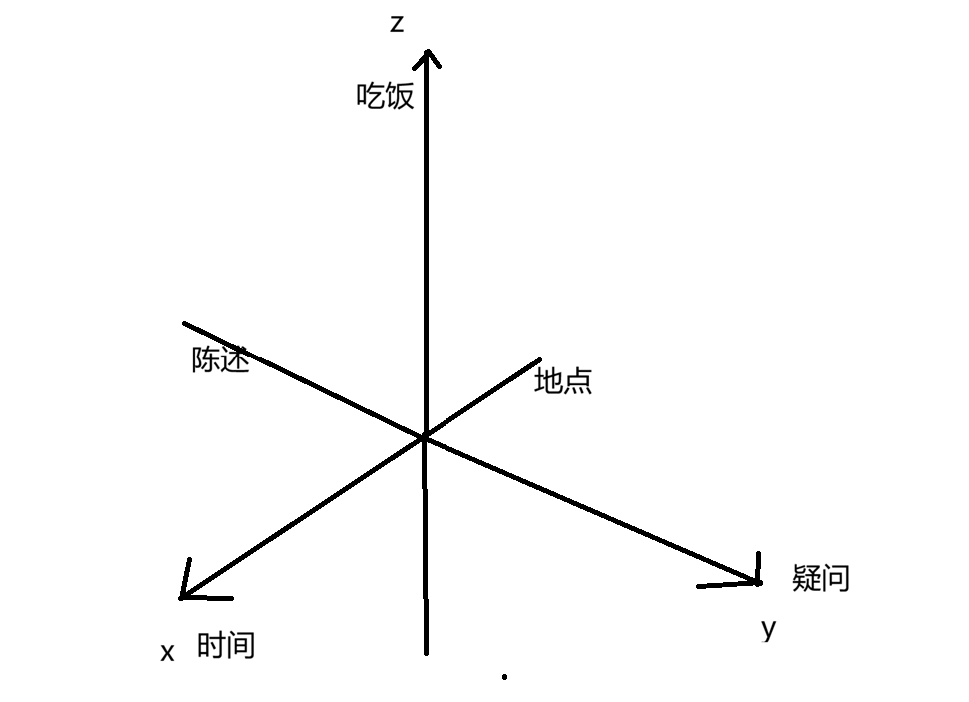
我们让每个方向代表不同的含义。
这时候我们想要表示”去哪吃饭?“,非常简单:
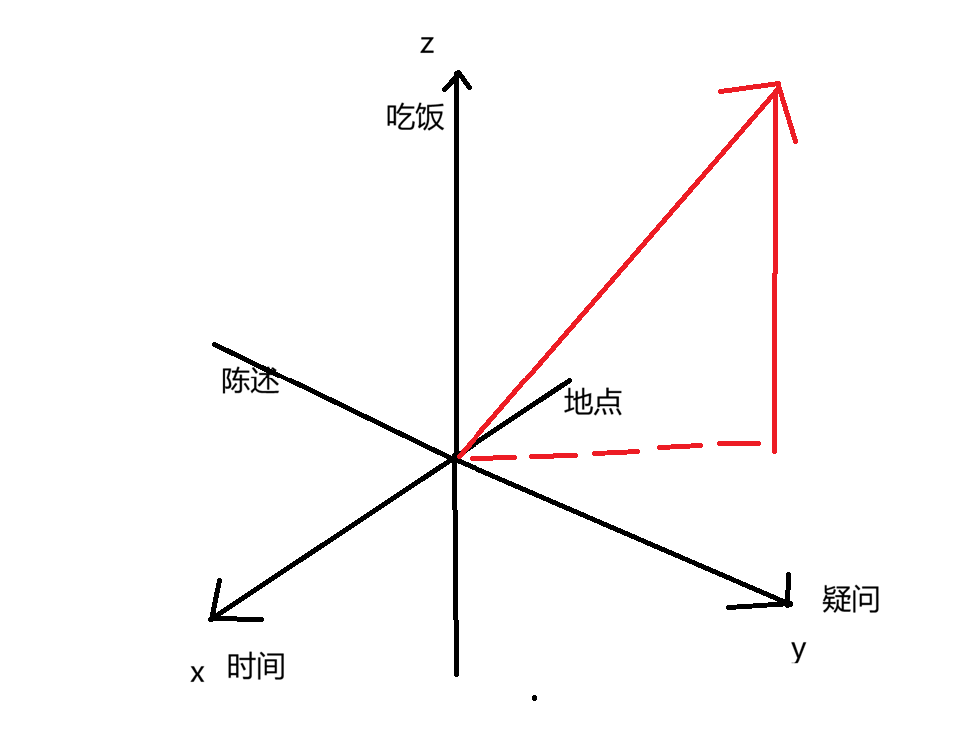
我们靠一个向量就解析了“去哪吃饭?“的语义——疑问+地点+吃饭。
而向量化文本就是在处理这些信息。模型的每个Token也是在处理这些信息。
RAG——即向量化文本存储,本质上就是通过训练一个模型,让模型读懂某些词和某些话代表的含义,并将其映射到一个超高维度的向量空间中——挨得很近的向量他们的语义就很类似。
我们只需要把一段很长的文本分割成很多小块,然后分别丢给向量化模型让他输出语义向量,我们就可以对这些内容进行检索。
模型内部权重也是有这么一个Token语义的解析,所以模型才能知道你说的每句话是愤怒还是悲伤,或者是严肃或者玩笑。
谈谈 Skill
Skill本质上就是一段注入到提示词中的、不用你每次手动输入的内容。他和你手动输入的内容没有任何区别。
而大部分Skill通常来说包括一些工具调用流程、API使用方法。
除此之外没有别的了。
谈谈 Prompt
写提示词也是一种手艺。反映了你对项目的理解程度、对bug定位的精准程度,都是对你水平的一次认定——不宽泛、详细描述架构、描述技术细节、描述问题所在等。
不然看别人写提示词:”帮我写一个浏览器“”为什么这里跑不通,给我修“”给我解决在家里能够运行但是离开家里就无法连接服务器的问题“等,真的是要吐血。
不过谈到提示词工程:从最开始的纯文本提示词,到现在发展的Markdown提示词、XML标签约束提示词等,都是在坚固模型的安全性和我们对目的描述的准确性。
一个好的提示词确实能够引导模型走向正确的答案。
这玩意其实也没啥好讲的。
谈谈 各个模型
前言:自从Claude的各个模型逐渐被移除Copilot Student后,我就很少用Anthropic的模型了。故Anthropic的说法仅供参考,还未使用Deepseek V4系列模型。
现在正确的模型使用方式应该是按照自己认为的解决问题能力分出固定模型和奇效模型,固定模型用于长期解决日常问题,奇效模型用于实在解决不出的bug进行几次尝试。就比如我是GPT5.4+Gemini3.1Pro。
在我看来,目前各几家的模型编码能力最强的还是GPT-5.5,其次是GPT-5.4和GPT-5.3Codex,再下一档就是Sonnet 4.5和Gemini 3.1 Pro。
国产模型我是基本不用于开发,一是Coding Plan太贵了,二是国模实力确实不够。
基本上GPT从5.2还是5.3开始,从自闭路线走向了类似于Claude的边写边有点输出的形式,而GPT在Copilot下更像是Gemini3.1那种COT+总结的方式。可能是Codex和Copilot的Agent工程有点差异。
况且OpenAI中转站还是非常省钱的,这点就已经足以在国内吊打其他场子了。
Copilot赚不到钱已经走向了没落,砍掉了5.4, 5.3codex和sonnet4.5,还加上了天限额、周限额,六月份还要全面从高级请求次数计数转向代币计费,评价为纯屎。
Google的One Pro适用,感觉周额度比Copilot还少,3.1系列模型和Opus/Sonnet都用几下就限额了,还要140块钱一个月,评价为也是纯屎。
End
至于接下来模型怎么发展,堆参数和训练方向的能有提升,但是在我看来并不是能有多大提升。
现在更长的上下文、更多的思考模式,也是在服务于特定场景Agent工程的需求。就像假如豆包每次你提问她都要先考虑一长串内容再给你回复,你会用他吗?
GPT-5.3Codex、GPT5.4、GPT5.5在我的任务范围用来基本没有非常大的提升。
更加令人兴奋的是下一个Agent爆点,和下一代LLM架构。